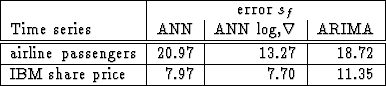

We compared our results with the results of the ARIMA procedure of the SAS software, an integrated system for data access, management, analysis and presentation. The implementation of the ARIMA procedure of SAS follows the programs described by Box and Jenkins in Part V of their classic [BJ76].
The ARIMA model is called an autoregressive integrated moving average process of order (p, d, q). It is described by the equation
![]()
![]()
![]()
![]()
We fitted an ARIMA model for each time series using the SAS system and let it predict the next 20 observations of the time series. The last 20 observations were dropped from the time series and used to calculate the prediction error of the models.
The following ARIMA models were calculated for the airline passenger time series (after a logarithmic transformation):
(1-z)(1-z12)Xt = (1 - 0.24169z - 0.47962z12) Ut
and for the IBM time series:(1-z) Xt = (1 - 0.10538z) Ut
As an opponent for the ARIMA modeling technique, we selected those networks that delivered the smallest forecast error sf for the respective time series data:
| series | # input | # hidden | ||
| units | units | |||
| airline | 0.1 | 0.9 | 70 | 45 |
| IBM | 0.1 | 0.9 | 80 | 30 |
In Table 2 the prediction errors for the artificial
neural network (ANN), the artificial neural network using the
logarithmic and ![]() transformation (ANN log,
transformation (ANN log,![]() ) and the
ARIMA model are compared: The artificial neural network using the
logarithmic and
) and the
ARIMA model are compared: The artificial neural network using the
logarithmic and ![]() transformed time series outperformed the
ARIMA models for both time series, whereas the ``simple'' artificial
neural network predicted more accurately only for the IBM shares time
series. This behavior can be explained as follows: the larger data
range of the airline passenger time series leads to a loss of
precision for the untransformed input set. Differencing and
logarithmic transformations helped to eliminate the trend and mapped
the time series data into a smaller range.
transformed time series outperformed the
ARIMA models for both time series, whereas the ``simple'' artificial
neural network predicted more accurately only for the IBM shares time
series. This behavior can be explained as follows: the larger data
range of the airline passenger time series leads to a loss of
precision for the untransformed input set. Differencing and
logarithmic transformations helped to eliminate the trend and mapped
the time series data into a smaller range.
| © 1997 Gottfried Rudorfer, © 1994 ACM APL Quote Quad, 1515 Broadway, New York, N.Y. 10036, Abteilung für Angewandte Informatik, Wirtschaftsuniversität Wien, 3/23/1998 |