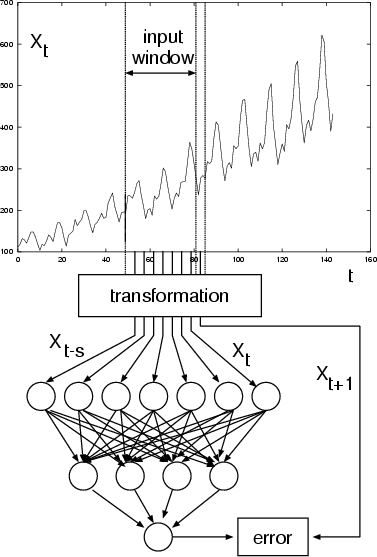

The neural network sees the time series ![]() in the form
of many mappings of an input vector to an output value (see figure
6). This technique was presented by [CMMR92].
in the form
of many mappings of an input vector to an output value (see figure
6). This technique was presented by [CMMR92].
A number of adjoining data points of the time series (the input window
![]() ) are mapped to the interval [0,1] and
used as activation levels for the units of the input layer. The size
s of the input window corresponds to the number of input units of
the neural network. In a forward path, these activation levels are
propagated over one hidden layer to one output unit. The error used
for the backpropagation learning algorithm is now computed by
comparing the value of the output unit with the transformed value of
the time series at time t+1. This error is propagated back to the
connections between output and hidden layer and to those between
hidden and output layer. After all weights have been updated
accordingly, one presentation has been completed. Training a
neural network with the backpropagation algorithm usually requires
that all representations of the input set (called one epoch) are
presented many times. In our examples, we used 60 to 138 epochs.
) are mapped to the interval [0,1] and
used as activation levels for the units of the input layer. The size
s of the input window corresponds to the number of input units of
the neural network. In a forward path, these activation levels are
propagated over one hidden layer to one output unit. The error used
for the backpropagation learning algorithm is now computed by
comparing the value of the output unit with the transformed value of
the time series at time t+1. This error is propagated back to the
connections between output and hidden layer and to those between
hidden and output layer. After all weights have been updated
accordingly, one presentation has been completed. Training a
neural network with the backpropagation algorithm usually requires
that all representations of the input set (called one epoch) are
presented many times. In our examples, we used 60 to 138 epochs.
For the learning of time series data, the representations were presented in a randomly manner: As reported by [CMMR92], choosing a random location for each representation's input window ensures better network performance and avoids local minima.
The next section is concerned with the selection of the right parameters for the learning algorithm and the selection of a suitable topology for the forecasting network.
| © 1997 Gottfried Rudorfer, © 1994 ACM APL Quote Quad, 1515 Broadway, New York, N.Y. 10036, Abteilung für Angewandte Informatik, Wirtschaftsuniversität Wien, 3/23/1998 |